


Back when I was a teenager, I was introduced by my dad to one of his young colleagues. This gentleman was considered an up-and-coming leader. He was smart and outgoing, and I was impressed by how everyone around him looked up to him, even people older and his superiors.
I hung on to every word he said. I started observing his mannerisms: how he dressed, how he carried himself, and even how he spoke. I then started emulating him. Even folded my sleeves (yes, I was a nerd) like him. However, within a few months of running into him at different events, I made a shocking discovery – he was a bigot. He repeatedly made disparaging comments about people of a particular religion. It was not even subtle, even around a kid like me. Fortunately for me, I grew up in a family where we were not exposed to such bigotry and were taught to be accepting of all. I soon started using my judgment, even at my age, to distance myself from this person, and even shared my concern about his behavior with my dad. I was able to discern which ‘features’ to emulate – his speaking style, the way he dressed, etc. – and which to ignore – his bigotry. Even as a teenager, I could choose what to learn and what not to.
Fast forward a few (ok, several) decades. Several weeks ago a picture was posted on Twitter of an AI-generated image generated by the prompt:
‘a close up photograph of the most beautiful 21-year-old woman alive, dramatic and stunning award winning photo, dramatic linear delicacy, shot on Sony aiii high resolution digital camera, hyper realistic skin, global illumination, very natural features, TIME cover photo, f/11 –uplight –ar 2:3 –q 2 –style raw –v 5.1’
The result was a beautiful, realistic image of a beautiful woman who was white-skinned.

This resulted in many questioning the bias of the AI (Midjourney) that generated it. Grady Booch commented. I too commented stating how an AI is not biased – it is at the end of the day an algorithm that has been trained on a data set – it is the data set that is likely biased. Unlike a human, even a child, it cannot choose what to learn and what not to. It learns all that is provided to it as its training data.
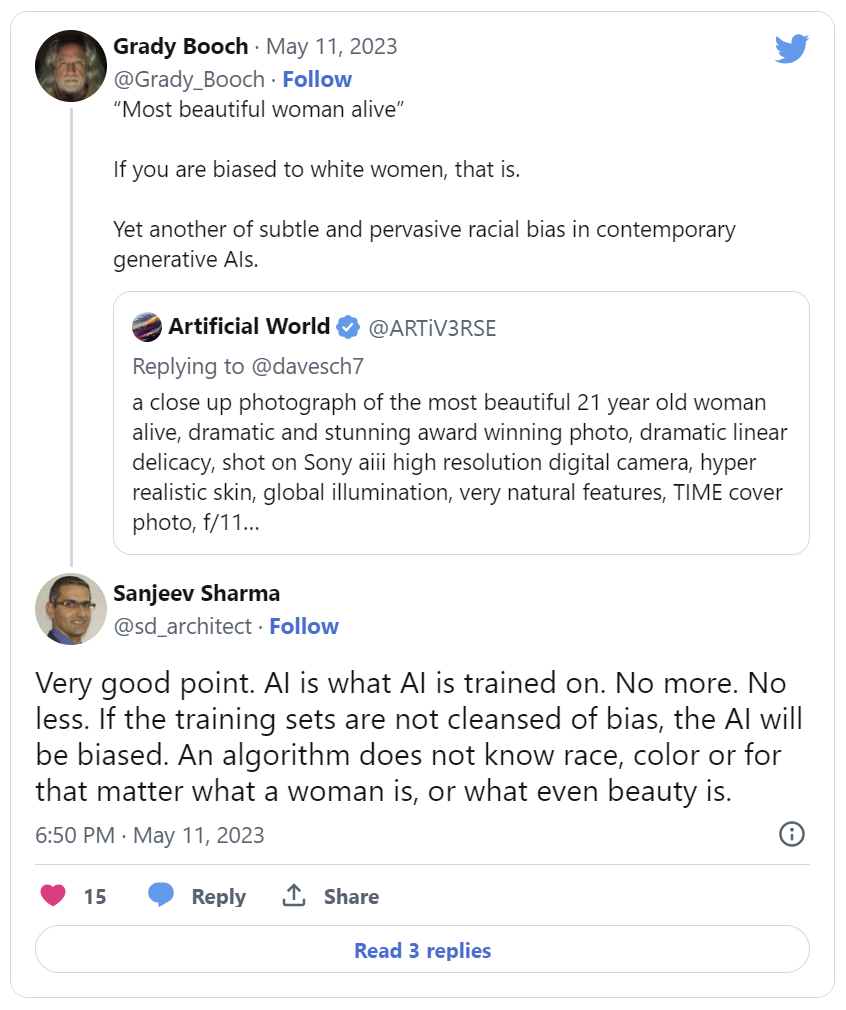
The AI Model that has been trained to generate this image, unlike teenager me, has no judgment. It cannot choose to learn from some data points in the training dataset and ignore others. It cannot discern bias when it sees it. It is, in this case, truly color-blind. The bias comes from the underlying dataset. The ‘judgment’ hence, needs to come from the person curating the dataset. They, the human dataset wranglers, need to be the ones who ensure that the dataset is void of any bias. In most cases, and it appeared in this one too, they failed to do so.
All this being said, on further thinking of the problem at hand, I now would like to argue that we do not know if the dataset training the model was what was biased. Is one point of data – one image – large enough of a sample set for us to judge? Can we run the generative AI prompt 1,000 times and then see what results we get? Do we get 1,000 identical images (identical responses)? That still does not prove bias. Or 1,000 different images? Well, now we can judge. If 1,000 different generated images are all of white women, we have identified bias. If they are a mix of races, then maybe not. We will need to see if the mix represents the same mix of races as the population of the world (Chinese and Indian being the largest set) or not. In a nutshell, this is not easy. Creating a training dataset that accurately represents the distribution of women by race in the population of the world is not a very reasonable expectation.
Wait, there’s more. If we do get mostly white women in the set of generated images, do we know why? Is the model actually biased? I would argue we are not really sure. Did the algorithm render an image of a white woman because its training data was overwhelmingly white women? Or did it do so because the prompt equated ‘most beautiful woman’ with Miss Universe winners whose pictures it had in its dataset, who have over the contest’s long history, predominantly been white women? Or did it choose a white woman because most ‘award-winning photos’ it found in its dataset were well, overwhelmingly white? Or did it do so because ‘Time cover photos’ have been mostly white people? Was it the model or the prompt that led to the result being a white woman? If instead, the user of the model had used some other words in his prompt, would the results have been a woman of a different race? Was it the model or the prompt structure that resulted in a white woman’s image being generated? Questions that cannot be answered by looking at the image. Were we all too quick to pass judgment on racial bias in the underlying model? We do not really know.
Training data bias is real. But so can be the ‘direction’ provided by the prompt. Judgment is not something the model can do. Or ever learn (except when we get AGI, which is for another blog post). That responsibility lies with the training data. But as my argument proves, also with the model user in how they structure their prompts. Bias-free AI is not on the cards right now, given building a dataset that is bias-free is not what will happen without focussed effort and judgment. Building such datasets is our responsibility. But it is also our responsibility to understand that how we word our prompts can result in bias.
The future is here. AI is being integrated into our lives as we speak. Datasets used to train models behind AI we are starting to use every day have not been properly documented, leaving the possibility of embedded bias. How a model parses prompts are a black box too. Allowing for the possibility that any bias in the results is driven not by the model but by the prompts. We, as AI builders and as users need to be aware of the infancy of the technology, and our understanding of how these models and promote parsers work is in. There is much to be learned. There is much judgment that needs to be built into the models and the prompts.
**This was reposted with permission from https://sdarchitect.blog/2023/06/14/ai-bias-and-judgement/.
About the Author
Sanjeev Sharma is an Internationally renowned Cloud Adoption, DevOps/DevSecOps Transformation, and Data Modernization Executive. Industry Analyst, Thought Leader, Technology and Strategy Advisor, Startup Advisor, Keynote Speaker, Blogger, Podcaster, YouTuber, and bestselling Author. Author of ‘The DevOps Adoption Playbook’, and ‘DevOps For Dummies, IBM Edition’. Keynote speaker at global IT conferences.
About Modev
Modev believes that markets are made and thus focuses on bringing together the right ingredients to accelerate market growth. Modev has been instrumental in the growth of mobile applications, cloud, and generative AI, and is exploring new markets such as climate tech. Founded in 2008 on the simple belief that human connection is vital in the era of digital transformation, Modev makes markets by bringing together high-profile key decision-makers, partners, and influencers. Today, Modev produces market-leading events such as VOICE & AI, and the soon to be released Developers.AI series of hands-on training events. Modev staff, better known as "Modevators," include community building and transformation experts worldwide.
To learn more about Modev, and the breadth of events offered live and virtually, visit Modev's website and join Modev on LinkedIn, Twitter, Instagram, Facebook, and YouTube.

